
Key Highlights
- Revolutionary Hybrid Model: India’s DPIIT proposes a mandatory blanket licensing system—unique globally—where AI companies must pay government-set royalties to a centralized fund (CRCAT) for using copyrighted content in training, regardless of where the AI company operates.
- CRCAT: The Centralised Mechanism: A new umbrella body, Copyright Royalties Collective for AI Training, will collect royalties from AI developers and proportionally distribute them to creators across multiple classes (text, music, images, video), streamlining compliance and ensuring unregistered creators also benefit.
- DNPA’s Legal Battle: India’s major news publishers (The Indian Express, NDTV, Hindustan Times) have joined ANI’s Delhi High Court lawsuit against OpenAI, alleging unlawful use of copyrighted news articles to train ChatGPT without license or compensation, testing whether AI training constitutes reproduction under Indian law.
- Global Divergence: While the US relies on fair-use doctrine and the EU allows TDM with opt-outs, India chooses mandatory collective licensing, positioning itself as a creator-centric, interventionist alternative—a potential model for the Global South.
The Problem—Why Creators Are Angry
The Data Grab: A Silent Expropriation
When OpenAI trained ChatGPT, Google built Gemini, and Meta created Llama, they didn’t ask permission. They didn’t negotiate licenses. They didn’t pay. They simply scraped the internet—including millions of copyrighted books, news articles, academic papers, music, and images—and fed them into algorithms that learned to generate human-like text.
In India, this problem cuts deeper. OpenAI has acknowledged that India is its second-largest market and a potential future number one. Yet, Indian creators—journalists, authors, musicians, visual artists—have seen their life work used without consent, without negotiation, and crucially, without compensation. techcrunch
DNPA’s Intervention: The Legal Awakening
In January 2025, the news industry woke up. The Digital News Publishers Association (DNPA), representing 20 major publishers including The Indian Express, NDTV, Hindustan Times, and India Today Group, filed an intervention in the Delhi High Court’s ANI v OpenAI case. medianama
Their grievance was stark: OpenAI had built a multi-billion-dollar AI company on the backs of Indian journalists’ work. Meanwhile, OpenAI had signed licensing deals with major international publishers (TIME, News Corp, The Atlantic) but offered nothing to Indian media houses.
The message was clear: If OpenAI values journalism globally, why does it refuse to value it in India?
The Copyright Question Nobody Wants to Answer
Here’s the legal puzzle the Delhi High Court is grappling with: Does AI training constitute “reproduction” under the Copyright Act, 1957?
OpenAI’s defense has been blunt. Storing copyrighted content in a training dataset isn’t reproduction—it’s transformation. The company argues that copyright protects only the “expression” of ideas, not ideas or facts themselves. Using facts to train an AI model is therefore legally defensible.
But creators counter: If copyright doesn’t protect journalists’ articles or authors’ books during AI training, then what’s the point of copyright in the AI era?
This tension—unresolved in Indian courts—is what the DPIIT’s proposal attempts to sidestep through legislation.
Understanding the DPIIT Framework
The “One Nation, One License, One Payment” Model
On December 9, 2025, the Department for Promotion of Industry and Internal Trade released a 125-page working paper titled “One Nation, One License, One Payment: Balancing AI Innovation and Copyright.”
The proposal is radically simple: Rather than every AI company negotiating with every copyright holder (an impossible task), all AI companies get automatic, blanket access to all lawfully-accessed copyrighted content in exchange for paying mandatory royalties into a centralized fund. voice.lapaas
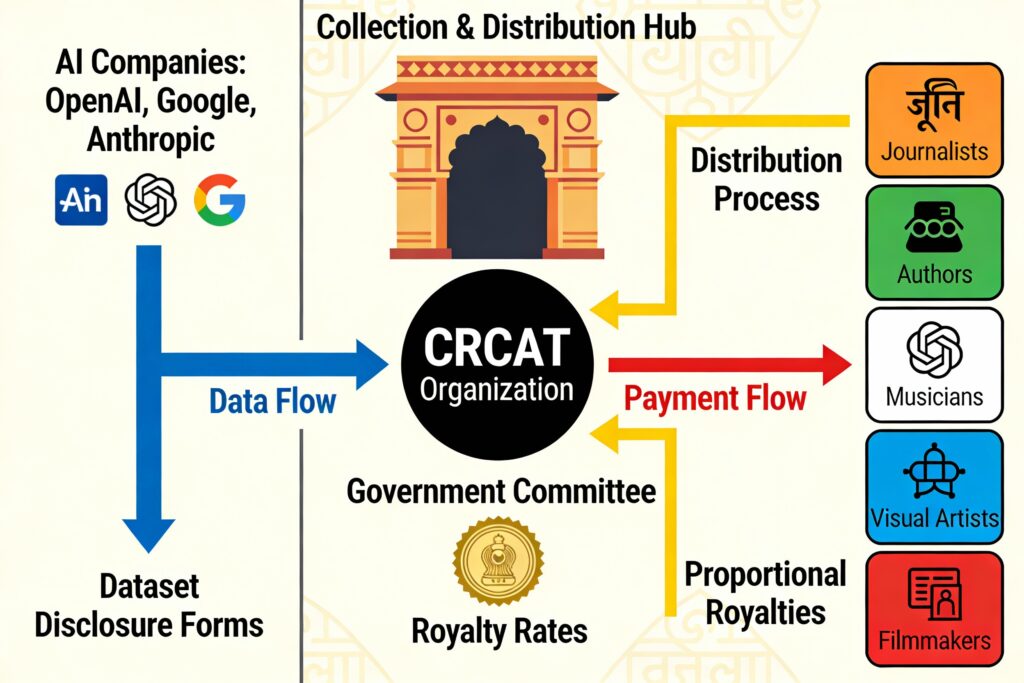
How the Royalty System Works
Step 1: Automatic Access
AI companies can train on any copyrighted content they lawfully access—downloaded from the internet, purchased, licensed—without asking permission. No negotiation required.
Step 2: Royalty Obligation Upon Commercialization
Once an AI system is deployed commercially and generating revenue, the developer must calculate its global revenue and pay a percentage (to be determined by a government committee) into the royalty pool.
Importantly, there are no retroactive upfront fees. Developers don’t pay during training or development—only upon commercialization. This is meant to encourage innovation without crushing startups before they launch.
Step 3: Government Committee Sets the Rate
A government-appointed Rate-Setting Committee—comprising senior officials, legal experts, financial/economic experts, technical experts, and representatives from CRCAT and the AI industry—will determine the percentage royalty rate.
This rate will apply universally to all AI firms, regardless of size, location, or business model.
Step 4: Retroactive Payment Obligation
Here’s the shock: The royalty obligation applies even for models already trained on copyrighted content and currently generating revenue. OpenAI and Google must pay for past usage of Indian content.
This is unprecedented globally and creates an immediate, massive liability for Big Tech.
CRCAT: The Centralized Collection Body
CRCAT will be a non-profit umbrella organization designated under the Copyright Act, 1957, composed of rights-holder associations and Collective Management Organisations (CMOs).
Key features:
- One member per class of work: One organization represents all text publishers, one represents music composers, one represents visual artists, etc.
- Works Database: Each CRCAT member maintains a registry where copyright holders can register their works.
- Data Disclosure: AI developers must submit a “Sufficiently Detailed Summary” of their training datasets—specifying categories (text, images, music), sources (social media, publications, libraries, proprietary data), and nature of use.
- Proportional Distribution: Royalties are allocated across classes of works based on their proportion in the disclosed training datasets.
- Unregistered Creator Protection: For sectors without existing CMOs, CRCAT temporarily holds royalties for up to three years, allowing creators to claim them retrospectively even if they weren’t registered upfront.
Key Design Rationale: The “Democratization” Argument
Why did DPIIT Additional Secretary Himani Pande and her committee choose mandatory licensing over TDM exceptions?
Their argument: Large players can negotiate. OpenAI has leverage; it can demand favorable terms from major publishers and secure licenses. But unorganized creators—freelance journalists, independent musicians, self-published authors—have zero bargaining power.
A mandatory, government-set system levels the playing field. Every creator, registered or not, gets compensated proportionally.
India’s Governance Dilemma—Constitutional and Policy Tensions
Property Rights vs. Collective Benefit
India’s framework creates a constitutional tension: Does mandatory collective licensing violate the property rights of copyright holders?
Under Article 19(1)(a) of the Constitution, individuals have freedom to carry on trade and business. This arguably includes the right to negotiate copyright terms directly with AI companies. ikigailaw
India’s proposed system restricts this freedom. A copyright holder cannot say “no” to AI training or negotiate individually—they must accept the government-set rate and CRCAT’s distribution mechanism.
While this benefits unorganized creators, it removes autonomy from established publishers who might secure better terms through direct negotiation.
The Innovation vs. Protection Paradox
India’s framework attempts to walk a tightrope: Encourage AI innovation (by granting blanket licenses) while ensuring creator protection (through mandatory payments).
But there’s a catch: Compliance costs will likely burden Indian startups more than global giants.
A 5-10% royalty on global revenue might be a rounding error for OpenAI ($80+ billion) or Google ($280+ billion). But for an Indian AI startup generating $1 million revenue, a $50-100K royalty payment is catastrophic.
Result: Consolidation. Big players survive. Smaller competitors exit. The market concentrates.
Enforcement Against International Companies: The Jurisdiction Problem
Here’s a logistical nightmare: How does India enforce royalty payments against a US-based AI company that operates globally?
OpenAI has already argued to the Delhi High Court that Indian courts lack jurisdiction over its AI training activities because the training happens on US servers.
If CRCAT cannot verify that a company has actually trained on Indian content, or cannot calculate “global revenue” accurately (when revenue is allocated across multiple jurisdictions), enforcement collapses.
The framework assumes cooperation from Big Tech. If they resist, India’s regulatory power is limited.
International Comparison—Why India Chose a Different Path
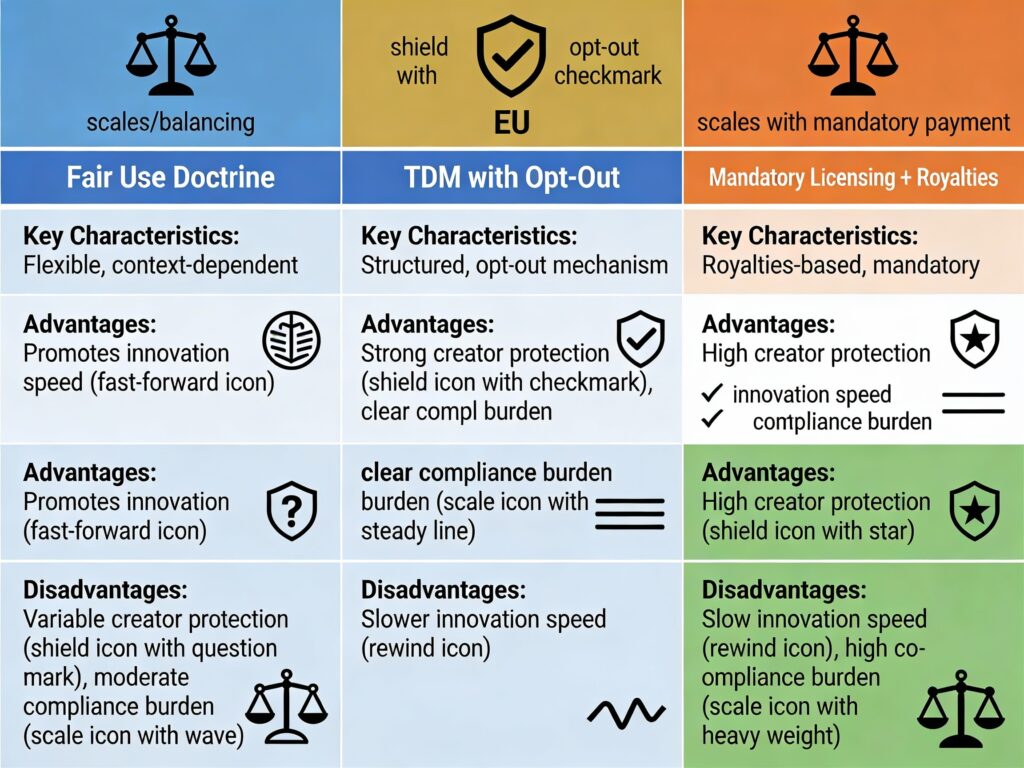
The US Model: Fair Use and Judicial Flexibility
The US approach trusts courts to determine fairness on a case-by-case basis.
Recent judgments (Bartz v Anthropic, Kadrey v Meta, both June 2025) have held that using copyrighted works to train AI models is transformative fair use because the resulting model serves a different purpose than the original works.
In Judge Alsup’s analysis: Teaching a model to analyze patterns is “spectacularly transformative”—as different from reading a book as learning from it.
Advantages: Flexibility, encourages innovation, no upfront licensing burden.
Disadvantages: Legal uncertainty, litigation risk, individual creators cannot defend rights alone.
The EU Model: TDM Exception with Opt-Out Rights
The EU’s DSM Directive (2019) allows text and data mining for any purpose with an important carve-out: copyright holders can opt out if they explicitly reserve rights in machine-readable format.
Recent cases (Amsterdam District Court, 2024) have clarified that opt-outs must use specific technical standards. Rights holders cannot rely on general website terms; they must implement machine-readable signals that AI companies can detect and respect.
The EU also strengthened this through its AI Act (2025), which mandates transparency: AI developers must disclose training data content and respect opt-outs on pain of regulatory penalty.
Advantages: Allows innovation; gives creators an opt-out mechanism; transparent frameworks.
Disadvantages: Opt-out is cumbersome and technically demanding; most creators never bother; big players often ignore small opt-outs.
Japan’s Approach: The Broadest TDM Exception
Japan allows the broadest TDM exception globally: any lawfully accessed content can be used for AI training with virtually no restrictions, no licensing, no opt-outs.
The rationale: Maximizing innovation and dataset access for Japanese AI developers.
Result: Japan has a thriving AI ecosystem with minimal copyright friction. But Japanese creators receive nothing.
India’s Hybrid: Mandatory Licensing with Government Rate-Setting
India rejects all three approaches and creates a fourth model: mandatory collective licensing with government-determined rates.
| Aspect | USA (Fair Use) | EU (TDM + Opt-Out) | Japan (Broad TDM) | India (Mandatory Licensing) |
|---|---|---|---|---|
| Baseline Access | Judicial determination | Broad TDM exception | Broad TDM exception | Automatic blanket license |
| Creator Protection | Case-by-case litigation | Opt-out mechanism | Minimal | Mandatory statutory royalties |
| Compensation Model | None (fair use doctrine) | None (unless contract) | None | Government-set percentage |
| Innovation Incentives | High (legal certainty) | High (minimal licensing) | Very high (no licensing) | Medium (compliance costs) |
| Regulator Role | Courts | Opt-out registries + EU authorities | Minimal | Central govt committee + CRCAT |
| Creator Bargaining Power | Low (fair use limits leverage) | Medium (opt-out possible) | Minimal | High (guaranteed share) |
Critical Governance Issues
Governance and Constitutional Frameworks
Problem 1: Rate-Setting Committee Independence
Who decides the royalty percentage? A government committee. But what prevents regulatory capture—where big AI companies lobby the committee for lower rates, or content cartels push for unreasonably high rates?
Unlike judicial fair-use determinations (which are transparent, appealable, and precedent-based), committee decisions on royalty rates could be opaque and politically influenced.
Problem 2: Balancing Fundamental Rights (Article 19)
- For AI companies: Article 19(1)(a) grants freedom to carry on trade. Mandatory licensing restricts this.
- For creators: The same article grants freedom to receive fair compensation for one’s labor and intellectual property.
- The dilemma: These rights conflict. India’s framework privileges creator rights over developer autonomy.
Is this constitutionally defensible? Likely yes (the state can impose reasonable restrictions for public good), but it’s contestable.
Problem 3: Institutional Design of CRCAT
Will CRCAT be truly independent, or will it become another government-dominated rights-collection body—like India’s music societies, which have been criticized for opacity, slow disbursement, and favoritism toward registered organizations?
International Relations and Trade Implications
Extraterritorial Reach
India is imposing royalty obligations on global AI companies based on their worldwide revenue, not just Indian market revenue.
If OpenAI’s global revenue is $100 billion, India would apply its royalty rate to that entire figure, even though most of that revenue comes from non-Indian users.
This creates tension with international trade law. WTO rules generally prohibit one country from taxing/regulating another country’s income. If India’s framework is challenged as discriminatory or extraterritorial, it could trigger trade disputes.
Comparative Disadvantage vs. TDM-Friendly Jurisdictions
If rates are seen as onerous, AI companies may shift training to TDM-friendly jurisdictions (Japan, parts of Europe) where there’s no royalty obligation.
Result: India loses AI investment and talent.
Impact on India’s AI Startup Ecosystem
The Startup Burden
Indian AI startups developing medical imaging, agricultural AI, or language models will face mandatory royalties. Global competitors in TDM-friendly jurisdictions face none.
This structural disadvantage could slow India’s emergence as an AI innovation hub.
The Data Access Question
One of India’s proposed benefits: startups get access to quality copyright-protected datasets (high-quality news articles, academic papers, fiction) for AI training, legally and legitimately.
But if royalty rates are high, startups might resort to cheaper, lower-quality, or uncopyrighted datasets, reducing training quality and potentially increasing bias.
Copyright Act Modernization
India’s Copyright Act, 1957 predates the internet, software, and AI. The 161st Parliamentary Standing Committee Report found it “not well equipped” to handle AI-era challenges.
Specific gaps:
- No definition of authorship for AI-generated works: If an AI generates an image, who owns it?
- No TDM exception: While EU and Japan have explicit TDM carve-outs, India’s Act is silent.
- No data attribution standards: How to track which copyrighted works contributed to AI models?
The DPIIT’s royalty framework is a patch, not a comprehensive modernization.
The ANI v OpenAI Case—India’s Copyright Test

The Delhi High Court’s ongoing case between ANI and OpenAI will fundamentally shape India’s copyright doctrine and determine whether the DPIIT framework is even necessary.
The Central Questions
- Is AI training reproduction? If yes, OpenAI violated copyright. If no, it’s legal.
- Is it fair dealing? Even if training is reproduction, does Section 52 of the Copyright Act protect it as fair dealing (like quoting for criticism or review)?
- Does Indian law apply? OpenAI argues its servers are in the US; Indian courts lack jurisdiction.
The Publishers’ Coalition
Beyond ANI, the Federation of Indian Publishers and DNPA have filed interventions.
Their collective argument: OpenAI admits signing licenses with international publishers. This proves OpenAI recognizes a licensing obligation. The company’s refusal to license Indian content is not legal necessity but commercial choice.
What a Favorable Judgment Could Mean
If the Delhi High Court rules that AI training is reproduction and not fair dealing, creators get immediate legal leverage. Existing lawsuits become powerful.
But if the court rules in OpenAI’s favor (likely given recent US precedent), the DPIIT’s mandatory licensing framework becomes the only legislative solution.
The Road Ahead—Policy Recommendations
The DPIIT’s proposal is Part 1 of a two-part report. Part 2 (due in ~2 months) will address ownership and authorship of AI-generated content.
The public consultation period (30 days post-December 9) will reveal whether the government refines the framework in response to industry and civil-society feedback.
Recommendations for Policymakers
1. Clarify and Strengthen Copyright Act
Amend the Copyright Act, 1957 to include:
- Explicit recognition of TDM exceptions for non-commercial, research, and transformative uses
- Definitions of authorship and ownership for AI-generated content
- Standards for dataset attribution and transparency
2. Make the Rate-Setting Committee Truly Independent
- Include diverse expertise (legal, economic, technical, creator, developer)
- Publish rate-setting methodology transparently
- Allow judicial review with meaningful scrutiny of arbitrary rates
3. Implement Tiered Royalty Rates
Instead of a universal rate for all AI companies:
- Tier 1 (Large commercial GenAI): Full rate (e.g., 5-10% of global revenue)
- Tier 2 (Mid-size AI services): Reduced rate (e.g., 2-5%)
- Tier 3 (Non-profit research, open-source, education): Zero or nominal rate
This protects startups and research while ensuring big players contribute.
4. Ensure CRCAT Transparency and Accountability
- Publish annual reports on royalty collection and distribution
- Allow independent audits
- Create grievance mechanisms for creators and developers
- Represent unregistered creators through government-appointed trustees
5. Coordinate Internationally
- Negotiate mutual enforcement agreements with major AI-developing countries
- Harmonize standards with EU’s AI Act transparency requirements
- Participate in global standard-setting for machine-readable opt-outs and dataset disclosures
For Creators: Preparing to Benefit
If the framework is implemented, creators should:
- Register works with CRCAT members (once CRCAT is operational)
- Track where their content appears in AI training datasets
- Participate in collective bargaining through CMO/industry bodies
- Document evidence of unauthorized use for legal leverage
Conclusion: India’s Fork in the Road

India’s “One Nation, One License, One Payment” proposal is bold, innovative, and globally significant. It represents a conscious choice to prioritize creator welfare over frictionless innovation—a departure from the Silicon Valley ethos that has dominated tech policy globally.
If implemented well—with transparent rate-setting, robust CRCAT governance, tiered rates for different developer scales, and careful international coordination—India’s framework could become a template for creator-centric AI regulation that other developing economies adopt.
If implemented poorly—with opaque committees, high rates stifling startups, corrupt CRCAT operations, and unenforced obligations—it could backfire spectacularly, driving AI investment away from India and consolidating market power among compliant incumbents.
The coming months—with Part 2 of the report, 30-day public consultation, parliamentary scrutiny, and ongoing ANI v OpenAI litigation—will shape whether this framework becomes India’s gift to global tech governance or a cautionary tale about well-intentioned regulatory overreach.
For UPSC aspirants, this issue exemplifies 21st-century governance challenges—balancing innovation with fairness, managing international dimensions of domestic regulation, protecting vulnerable stakeholders (creators) from powerful corporations, and modernizing legal frameworks for technological disruption.
Key Terms Glossary
| Term | Definition |
|---|---|
| Blanket License | Single license granting access to all works in a category without individual permissions. |
| Text and Data Mining (TDM) | Automated analysis of digital content to extract patterns and information. |
| Fair Use/Fair Dealing | Legal doctrine allowing limited use of copyrighted material without permission for purposes like criticism, commentary, research. |
| Transformative Use | Use that adds new expression, meaning, or purpose, potentially qualifying for fair use. |
| Extended Collective Licensing (ECL) | System where collective agreements cover non-members, ensuring universal compensation. |
| CRCAT | Copyright Royalties Collective for AI Training; India’s proposed central royalty collection and distribution body. |
| Statutory Licensing | Government-mandated licensing with rates set by law, not negotiation. |
| Retroactive Payment | Payment obligation for past usage of content, not just future usage. |
| Rate-Setting Committee | Government-appointed body determining royalty percentage to be paid by AI companies. |
| Works Database | Registry maintained by CRCAT members where creators register their copyrighted works. |
UPSC Practice Questions
Mains Questions (250 words each)
Q1: Governance Framework
The DPIIT’s mandatory blanket licensing for AI training represents a paradigm shift from voluntary licensing negotiation to statutory collective compensation. Critically examine the policy rationale, implementation challenges, and constitutionality of this approach in balancing creator rights, developer freedoms, and innovation incentives. (GS-II, 250 words)
Q2: Comparative Policy Analysis
Compare India’s proposed AI copyright framework with the approaches of the United States (fair use doctrine), European Union (TDM exception with opt-out), and Japan (liberal TDM exception). What are the strengths and weaknesses of each model for developing economies? (GS-II/III, 250 words)
Q3: Innovation and Development
“While India’s proposed royalty framework protects creator interests, it risks disadvantaging domestic AI startups and consolidating market power among global giants.” Analyze this statement with reference to India’s AI policy objectives and economic implications. (GS-III, 250 words)
Ethics Case Study
An Indian filmmaker discovers that their copyrighted film has been used without permission to train an AI video generation model operated by a major tech company. Under the DPIIT’s proposed framework, they would be automatically entitled to a share of royalties determined by a government committee. However, the royalty percentage is lower than what direct negotiation might yield. Additionally, the filmmaker values creative control and prefers to withhold their work entirely. What ethical and practical considerations should guide their decision-making? Discuss with reference to individual rights, collective welfare, and optimal policy design. (GS-IV Ethics, 400 words)







+ There are no comments
Add yours